10G B14211-01
今天起开始阅读Oracle® Database Performance Tuning Guide 10g Release 2 (10.2)
这篇主要讲述10G性能调整的方方面面,虽然有关性能的话题总是牵连广泛,比如底层硬件,CPU,内存,网络,存储,firmware版本,RAID,OS,内核版本,内核参数....但是这里主要关注如何在其他因素确定的情况下,调整Oracle的性能。
今天起开始阅读Oracle® Database Performance Tuning Guide 10g Release 2 (10.2)
这篇主要讲述10G性能调整的方方面面,虽然有关性能的话题总是牵连广泛,比如底层硬件,CPU,内存,网络,存储,firmware版本,RAID,OS,内核版本,内核参数....但是这里主要关注如何在其他因素确定的情况下,调整Oracle的性能。
最近我在看10g RMAN的文档,如何利用rman进行高级复制,重建数据库。
还有就是对照OCM的考试大纲一个一个的练习和做实验。
准备今年内参加OCM的考试。
英语啊英语,我的口语怎么练习呢?
很想背一背,但是找不到好的材料。
do.bat
@echo Straing load COC data from ADE tab flat file
@for /f %%A in ('"dir /a:d /b "') do @dir %%A /s /b >> temp.tmp
@rem 这里首先取到当前目录下面的所有子目录中的文件(只有一层),保存在temp.tmp里面
@find "TEX" temp.tmp > temp.names
@rem 过滤temp.tmp的内容,之保留带有TEX结尾的文件。
@for /f "skip=2" %%A in ('"type temp.names "') do @call extract %%A
@rem 用extract脚本收取每个文件当中的内容
@REM *********************
@for /f %%A in ('"dir /a:d /b "') do @rd %%A /q /s
@del temp.tmp
@del temp.names
@del temp.log
@del temp.bad
@rem 收尾工作
@echo wwwwwwwwwwwwwwwwork is doneeeeeeeeeeeeeeeeee
extract.bat
@echo in
@sqlldr userid=COC_COLLECTION/coc@mycim control=extractData.ctl data=%1 skip=200 log=temp.log bad=temp.bad
@sqlldr userid=COC_COLLECTION/coc@mycim control=extractParameter.ctl data=%1 log=temp.log bad=temp.bad
@sqlldr userid=COC_COLLECTION/coc@mycim control=extractOrder.ctl data=%1 log=temp.log bad=temp.bad
@sqlplus COC_COLLECTION/coc@mycim @run.txt
@echo out
extractData.ctl
OPTIONS (ERRORS=10000, SILENT=(ALL), READSIZE=2097152 )
load data
infile *
replace INTO TABLE data
(
CLASSNUM position(1:7) "case when to_char(:CLASSNUM) like '%****%' then null else to_number(:CLASSNUM) end",
AMOUNT position(*:16) "case when to_char(:AMOUNT) like '%****%' then null else to_number(:AMOUNT) end",
MAX position(*:24) "case when to_char(:MAX) like '%****%' then null else to_number(:MAX) end",
MIN position(*:33) "case when to_char(:MIN) like '%****%' then null else to_number(:MIN) end",
MEAN position(*:42) "case when to_char(:MEAN) like '%****%' then null else to_number(:MEAN) end",
DELTA position(*:51) "case when to_char(:DELTA) like '%****%' then null else to_number(:DELTA) end",
MAX_DEV position(*:60) "case when to_char(:MAX_DEV) like '%****%' then null else to_number(:MAX_DEV) end",
STD_DEV position(*:69) "case when to_char(:STD_DEV) like '%****%' then null else to_number(:STD_DEV) end",
CV position(*:78) "case when to_char(:CV) like '%****%' then null else to_number(:CV) end"
)
extractParameter.ctl
OPTIONS (ERRORS=10000, SILENT=(ALL), READSIZE=2097152 )
LOAD DATA
INFILE *
REPLACE
CONTINUEIF THIS (1) = '"'
INTO TABLE para
(
a terminated by '"' "case when to_char(:a) is null then 'notmeasured' else to_char(:a) end",
b terminated by 'Total'
)
extractOrder.ctl
Load data
infile *
replace
INTO TABLE po
WHEN (2:12) = 'Plant Order'
(
PO position(13:100)
)
这篇文章主要向你介绍,如何在只有一块物理硬盘的linux环境下,安装带ASM的Oracle 10g。
首先用grub引导机器,进入grub的命令行。
kernel (hd0,10)/as4/vmlinuz
Initrd (hd0,10)/as4/initrd.img
boot
然后从硬盘选择iso镜像,安装Red hat AS4u4。
Oracle 10g的安装选择silent模式。
1. 省略前期的内核配置,用户权限配置,用户环境变量配置。
2. 录制安装脚本
$./runInstaller –record –destinationFile /tmp/install_scripts.rsp
进入安装界面后,按照需求选择,最后一步的时候cancel掉。(注意选择software only)
3. 使用录制脚本安装
$./runInstaller –silent –force –ignoreSysprereqs –responseFile /tmp/install_scripts.rsp
4. Post installation actions
步骤3结束以后,需要运行两个脚本。
$ORACLE_BASE/oraInvntory/orainstRoot.sh
$ORACLE_HOME/root.sh
至此Oracle 10g R2安装结束。
5. 卸载
$./runInstaller –silent –deinstall –removeallfiles –removeAllPatches –responseFile /tmp/install_scripts.rsp
ASM
Automatic Storage Management是专门为Oracle数据库提供的一个逻辑卷管理器,提供数据条带化,磁盘IO负载均衡以及数据冗余。
通常情况下,ASM建立在若干硬盘之上,这样可以保证数据冗余以及IO负载均衡。
由于是在笔记本上搭建这样的环境,我只有一个硬盘,那么就需要通过loopback devices来模拟多个硬盘。
下面介绍整个ASM的安装过程
1. 制作“本地磁盘”
创建一个目录
mkdir /asmdisks
创建若干用来模拟本地硬盘的大文件。由于在linux下,touch命令产生的稀疏文件,所以这里使用dd命令。
dd if=/dev/zero of=/asmdisks/disk1 bs=1024k count=1000
dd if=/dev/zero of=/asmdisks/disk2 bs=1024k count=1000
dd if=/dev/zero of=/asmdisks/disk3 bs=1024k count=1000
dd if=/dev/zero of=/asmdisks/disk4 bs=1024k count=1000
dd if=/dev/zero of=/asmdisks/disk5 bs=1024k count=1000
我在这里生成了5个1GB的文件,并且全部用0来填充。losetup命令可以将这5个大文件‘变成‘5个本地磁盘。
losetup /dev/loop1 /asmdisks/disk1
losetup /dev/loop2 /asmdisks/disk2
losetup /dev/loop3 /asmdisks/disk3
losetup /dev/loop4 /asmdisks/disk4
losetup /dev/loop5 /asmdisks/disk5
现在就可以对这5个设备进行格式化了,使用任何一种我们喜欢的文件系统。
2. 安装ASM类库
ASM的安装需要Oracle提供的asm类库支持,可以在这里http://www.oracle.com/technology/tech/linux/asmlib/index.html 下载到。下载的时候注意自己机器的配置,用uname -a查看。
oracleasm-support.rpm
oracleasm-2.6.9-42-x86_64.EL.rpm
oracleasmlib.rpm
为了让机器每次重启的时候,都让系统自动加载ASM并配置好的权限,我们需要运行以下命令。
/etc/init.d/oracleasm configure
oracle
oinstall
y
y
3. 配置ASM磁盘组
/etc/init.d/oracleasm createdisk ASMD1 /dev/loop1
/etc/init.d/oracleasm createdisk ASMD2 /dev/loop2
/etc/init.d/oracleasm createdisk ASMD3 /dev/loop3
/etc/init.d/oracleasm createdisk ASMD4 /dev/loop4
/etc/init.d/oracleasm createdisk ASMD5 /dev/loop5
4. 创建ASM实例
传统的逻辑卷都有逻辑卷管理器,ASM的逻辑卷管理器就是一种Oracle实例,但是一种特殊的实例。没有buffer cache和log buffer因为它不需要open一个database。ASM实例有large pool和shared pool以及一些特殊的后台进程
以root身份运行
/oracle/10g/bin/localconfig add
换成oracle用户,编辑+ASM实例的参数文件
INSTANCE_TYPE=ASM
DB_UNIQUE_NAME=+ASM
LARGE_POOL_SIZE=8M
ASM_DISKSTRING=ORCL:*
启动ASM实例
export ORACLE_SID=+ASM
sqlplus / as sysdba
create diskgroup DGROUP1 normal redundancy
disk 'ORCL:ASMD1','ORCL:ASMD2','ORCL:ASMD3',
'ORCL:ASMD4','ORCL:ASMD5';
在/etc/rc.local中加入如下内容:
/sbin/losetup /dev/loop1 /asmdisks/disk1
/sbin/losetup /dev/loop2 /asmdisks/disk2
/sbin/losetup /dev/loop3 /asmdisks/disk3
/sbin/losetup /dev/loop4 /asmdisks/disk4
/sbin/losetup /dev/loop5 /asmdisks/disk5
/etc/init.d/oracleasm createdisk ASMD1 /dev/loop1
/etc/init.d/oracleasm createdisk ASMD2 /dev/loop2
/etc/init.d/oracleasm createdisk ASMD3 /dev/loop3
/etc/init.d/oracleasm createdisk ASMD4 /dev/loop4
/etc/init.d/oracleasm createdisk ASMD5 /dev/loop5
5. 创建数据库
编辑参数文件init.ora
db_name=smart
sga_target=128M
db_create_file_dest=+DGROUP1
这里要注意,sga的不能太小,否则在创建数据库的时候会出现shared pool太小的错误。设置db_create_file_dest说明我们使用了OMF,Oracle Managed Files。
sqlplus “/ as sysdba”
create spfile from pfile;
shutdown immediate
startup nomount
create database;
create temporary tablespace temp;
create undo tablespace undotbs1;
@?/rdbms/admin/catalog
@?/rdbms/admin/catproc
alter database default temporary tablespace temp;
alter system set undo_tablespace=undotbs1 scope=spfile;
alter system set undo_management=auto scope=spfile;
startup force
6. 维护ASM
select name from v$datafile;
create tablespace DATA;
alter database datafile '+DGROUP1/smart/datafile/undotbs1.262.591694817' resize 120m;
alter database datafile '+DGROUP1/smart/datafile/undotbs1.262.591694817' autoextend off;
alter database datafile '+DGROUP1/smart/datafile/undotbs1.262.591694817' autoextend on next 10m;
7. 维护ASM文件
export ORACLE_SID=+ASM
asmcmd
添加ASM文件
$ su - root
# dd if=/dev/zero of=/asmdisks/disk6 bs=1024k count=1000
# /sbin/losetup /dev/loop6 /asmdisks/disk6
# /etc/init.d/oracleasm createdisk ASMD6 /dev/loop6
alter diskgroup DGROUP1 add disk 'ORCL:ASMD6';
alter diskgroup dgroup1 drop disk asmd6;
自我感觉,ASM就是一个专门为Oracle服务的,支持Oracle集群的软Raid。
参考 http://www.dizwell.com/prod/node/34
SQL> SELECT DBMS_METADATA.GET_DDL('TABLE','BLANK') FROM DUAL;
DBMS_METADATA.GET_DDL('TABLE','BLANK')
--------------------------------------------------------------------------------
CREATE TABLE "TEST"."BLANK"
( "A" VARCHAR2(100)
) PCTFREE 10 PCTUSED 4
SQL> SET LONG 2000
SQL> SELECT DBMS_METADATA.GET_DDL('TABLE','BLANK') FROM DUAL;
DBMS_METADATA.GET_DDL('TABLE','BLANK')
--------------------------------------------------------------------------------
CREATE TABLE "TEST"."BLANK"
( "A" VARCHAR2(100)
) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRAN
S 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEX
TENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS
1 BUFFER_POOL DEFAULT)
TABLESPACE "USERS"
DBMS_METADATA.GET_DDL('TABLE','BLANK')
--------------------------------------------------------------------------------
SQL>
OS:Windows XP pro
Oracle: 10.2.0.1 64bit
listener中
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 127.0.0.1)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1))
)
)
其他机器用tnsping这台机器的话,会得到TNS-12541错误,no listener。
用netstat -an发现
TCP 127.0.0.1:1521 0.0.0.0:0 LISTENING
远程机器telnet 192.168.1.8 1521无法连接。
HOST要配置成机器名,才能避免这样的错误。
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = linux)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1))
)
)
这个时候
TCP 0.0.0.0:1521 0.0.0.0:0 LISTENING
折腾了我一个下午啊,thanks acterm。
作者:feelfall
出处:feelfall.blogspot.com
转载时请保留作者和出处。
还是由于人懒,这篇文章没有写完。有兴趣再回头研究的时候,我会把这篇文章写完的。
信号量是一种描述共享资源的方法。
信号量分两种,一种是binary semaphore,一种counting semaphore。
在操作系统中,它是一种进程间通信(IPC)的重要手段。
锁是一种序列化机制,实现并发控制的一种手段,它强制那些使用资源的实体(如线程、进程)遵守某些规范(authorized or not. etc)。
锁从强制性分,有两种,一种是advisory lock(也称协作锁),一种是mandatory lock(强制锁)。
使用协作锁,控制权交由程序员来控制,进程或线程之间需要默契配合。这种锁不会防止程序员破坏自己的数据,使数据不一致。说白了,这种锁由user mode processes控制。
强制锁是内核控制检查的锁,这种锁一定会保证其约束条件。比如io scheduler调度不过来了,bio队列已满。
那么用户程序是不会在这个时候从操作系统得到资源的,必须被挂起。
锁从读取类型来分,也分两种,一种是shared lock,一种是exclusive lock。什么作用,这里不赘述了。
一个binary semaphore就可以是一个最简单的锁。
通常,锁是要求硬件支持的,以完成原子操作。
在多处理器的环境中,为了保证原子性,这些操作由处理器的特殊指令来实现,例如test-and-set,fetch-and-add或者是compare-and-swap。
可以防止interrupt破坏atomic operation。
嗯,是不是想起了oracle中的latch了?操作系统中是spin lock,oracle中是latch,目的差不多,防止并发修改,都是抢的。
用的cpu指令就是test-and-set,这是硬件提供的最底层的原子化操作。
现在说一下锁的粒度。
锁的粒度是指lock锁了多少资源。
锁粒度太小,会导致lock overhead。系统这个时候疲于应付反复initialize和destroy locks(内存资源)。用的锁越多,这个问题就越凸显。
粒度太大,会导致锁竞争。
信号量和锁之间是什么关系呢?
当进程试图访问一个被信号量保护的资源的时候,进程被挂起(进入sleep状态)。注意,申请使用信号量的函数都要是可以sleep的(中断和可延后程序就不行)。
当所需的信号量被释放,对应进程就会进入runnable状态,随时可以调度运行。
从Linux的角度看,序列化设备有spin lock,semaphore,(还有interrupt和softirq)。
从Oracle的角度看,序列化设备有latch lock和enqueue lock。latch使用test and set或者compare and swap,
先来简单看一下Linux的spin和semaphore结构。
------------------
|spinlock_types.h|
------------------
typedef struct {
unsigned int slock;
} raw_spinlock_t;
typedef struct {
raw_spinlock_t raw_lock;
#if defined(CONFIG_PREEMPT) && defined(CONFIG_SMP)
unsigned int break_lock;
#endif
#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} spinlock_t;
--------
|wait.h|
--------
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
----------
|atomic.h|
----------
typedef struct { volatile int counter; } atomic_t;
-------------
|semaphore.h|
-------------
struct semaphore {
atomic_t count;
int sleepers; 等待此信号量的进程数
wait_queue_head_t wait; 等待进程队列
};
我们再来看一下linux中spin的函数。(片段)
-----------------------------------------
|linux-2.6.20.1/arch/s390/lib/spinlock.c|
-----------------------------------------
int spin_retry = 1000;
static inline void _raw_yield(void)
{
if (MACHINE_HAS_DIAG44)
asm volatile("diag 0,0,0x44");
}
static inline void _raw_yield_cpu(int cpu)
{
if (MACHINE_HAS_DIAG9C)
asm volatile("diag %0,0,0x9c"
: : "d" (__cpu_logical_map[cpu]));
else
_raw_yield();
}
void _raw_spin_lock_wait(raw_spinlock_t *lp, unsigned int pc)
{
int count = spin_retry;
unsigned int cpu = ~smp_processor_id();
while (1) {
if (count-- <= 0) {
unsigned int owner = lp->owner_cpu;
if (owner != 0)
_raw_yield_cpu(~owner);
count = spin_retry;
}
if (__raw_spin_is_locked(lp))
continue;
if (_raw_compare_and_swap(&lp->owner_cpu, 0, cpu) == 0) {
lp->owner_pc = pc;
return;
}
}
}
int _raw_spin_trylock_retry(raw_spinlock_t *lp, unsigned int pc)
{
unsigned int cpu = ~smp_processor_id();
int count;
for (count = spin_retry; count > 0; count--) {
if (__raw_spin_is_locked(lp))
continue;
if (_raw_compare_and_swap(&lp->owner_cpu, 0, cpu) == 0) {
lp->owner_pc = pc;
return 1;
}
}
return 0;
}
void _raw_spin_relax(raw_spinlock_t *lock)
{
unsigned int cpu = lock->owner_cpu;
if (cpu != 0)
_raw_yield_cpu(~cpu);
}
void _raw_read_lock_wait(raw_rwlock_t *rw)
{
unsigned int old;
int count = spin_retry;
while (1) {
if (count-- <= 0) {
_raw_yield();
count = spin_retry;
}
if (!__raw_read_can_lock(rw))
continue;
old = rw->lock & 0x7fffffffU;
if (_raw_compare_and_swap(&rw->lock, old, old + 1) == old)
return;
}
}
int _raw_read_trylock_retry(raw_rwlock_t *rw)
{
unsigned int old;
int count = spin_retry;
while (count-- > 0) {
if (!__raw_read_can_lock(rw))
continue;
old = rw->lock & 0x7fffffffU;
if (_raw_compare_and_swap(&rw->lock, old, old + 1) == old)
return 1;
}
return 0;
}
void _raw_write_lock_wait(raw_rwlock_t *rw)
{
int count = spin_retry;
while (1) {
if (count-- <= 0) {
_raw_yield();
count = spin_retry;
}
if (!__raw_write_can_lock(rw))
continue;
if (_raw_compare_and_swap(&rw->lock, 0, 0x80000000) == 0)
return;
}
}
int _raw_write_trylock_retry(raw_rwlock_t *rw)
{
int count = spin_retry;
while (count-- > 0) {
if (!__raw_write_can_lock(rw))
continue;
if (_raw_compare_and_swap(&rw->lock, 0, 0x80000000) == 0)
return 1;
}
return 0;
}
这里使用了compare and swap指令。spin_retry也是可以调整的。
用下面这个命令查看semaphore的使用情况。
# ipcs -s
------ Semaphore Arrays --------
key semid owner perms nsems
0xd9895640 229376 oracle 640 154
一般来说结构越复杂,管理起来就越麻烦,相应的开销就越大。
然而对于不同的应用类型,比如一个只使用0.1ms的资源和一个要使用30s的资源,它们使用的序列化设备就应该不一样。
前者用spin,后者用semaphore。(注意到volatile没有?其实semaphore的count是受cpu的原子操作指令保护的)
Oracle的enqueue其实就是advisory lock方式(让oracle构筑自己的进程之间的序列化机制,kernel不会去强行干预),它使用semaphore来进行控制消息的传递。
比如LGWR在没有等到自己的semaphore的时候处于sleep状态。当得到自己的semaphore时LGWR开始干活,写出在线日志buffer。
这里稍微扯远点,当发生log file sync的时候,这里其实不是Oracle的锁的直接作用结果,而是系统的mandatory lock的间接产物,最终反映成log file sync。
首先,磁盘没有返回'写完成'的中断信号,OS的kernel级写线程的调度数量达到了上限,不允许用户进程再往里面塞bio,这时是mandatory lock。
ps:还有几种情况没有说,不把问题扯的太远,先说到这里,只是提一个不同lock mode,以后我还会写相关文章的。
在Linux上安装oracle的时候,我们通常要配置一下kernel的参数,其中就有shared memory也有semaphore相关的参数需要调整。
SHMMAX: 定义单个共享内存段的最大值。这只是一个上界值,如果使用时超过了这个值,那么会被分成多段。
SHMALL 可用共享内存的总数量(字节或者页面) 如果是字节,就和 SHMMAX 一样;如果是页面,ceil(SHMMAX/PAGE_SIZE)
*SEMMSL:定义一个semaphore set中的semaphore数量上限。system v ipc中不是一个一个获取semaphore的,当然了,你可以获取只包含一个semaphore的semaphore set,it's up to you。
上面看到semaphore arrays的结果就是一个semaphore set。oracle的每个instance都需要一个semaphore set。
每个instance要求这个内核参数至少等于oracle允许的进程数(oracle参数文件中的processes)。
*SEMMNI:定义系统中一共可以有多少个semaphore set。有什么用呢?
你要是想在一个机器上启动两个oracle instance,那么仅就oracle来说,这个数值就至少要为2(当然还可能有其他的应用需要semaphore set,而不仅是oracle)。
如果你在一个机器上启动了多个instance,那么你ipcs -s的时候,看到的条目就是多个了。
*SEMMNS:定义系统中允许的semaphore数量的最大值。这个就不用解释了吧。
*SEMOPM:定义每个semop()系统调用所允许完成的操作。前面这句话肯定没有说清楚问题:)。
这么说吧,你的进程申请资源的时候可以一下申请多种资源,对应的就是几个semaphore。
semop系统调用就是申请资源用的,SEMOPM这个内核参数就是限定semop这个玩意儿一次可以操作(修改)多少个semaphore。
带*的由kernel.sem 250 32000 100 128 in /etc/sysctl.conf
means SEMMSL, SEMMNS, SEMOPM, and SEMMNI.
SEMVMX:定义......回到上面的struct semaphore,这里限定的就是count的最大值。也就是semaphore反映的资源数上限。
SEMMNU:定义系统中semaphore undo structrue的数量。当进程意外终止时,这种回滚结构可以保护相应的资源。SEMMNU这个参数值最好大于系统可能的最大进程数。
Oracle's latches and enqueues
latch:栓。
latch和spin的设计目标是一样的,都是以对象被锁定时间不长为前提的。
latch保护SGA里那些不能被并发修改的数据(排他的)。通常每种结构只需要一个latch就够了。
所以latch通常不被用来做shared access。
当处理器A持有某个资源的ltach,处理器B就不可以去使用这个资源。(有例外,不讲例外:D)
但是这个时候处理器B不会善罢甘休,它会不停的去test and set,试图得到这个资源。
为了不让B永远试下去,它进行test and set的次数是被限制的,由_SPIN_COUNT隐含参数确定(和linux中的spin_retry差不多)。
达到这个次数后,运行在B上的进程会去休息会儿。
休息多久呢?这由一个指数后退算法(这让我想起了上学时模拟的CSMA/CD)加参数_MAX_EXPONENTIAL_SLEEP来确定,
如果这个process还有别的latch,那么综合考虑,参数使用_MAX_SLEEP_HOLDING_LATCH。
我机器上的配置情况如下:
select b.KSPPINM as name,a.ksppstvl as value,b.KSPPDESC as description
from X$KSPPCV a, X$KSPPI b
where a.indx=b.indx and b.ksppinm = '_spin_count'
NAME VALUE DESCRIPTION
-------------------- ---------- ----------------------------------------
_spin_count 2000 Amount to spin waiting for a latch
select b.KSPPINM as name,a.ksppstvl as value,b.KSPPDESC as description
from X$KSPPCV a, X$KSPPI b
where a.indx=b.indx and b.ksppinm = '_max_exponential_sleep'
NAME VALUE DESCRIPTION
------------------------------ ---------- ----------------------------------------
_max_exponential_sleep 0 max sleep during exponential backoff
select b.KSPPINM as name,a.ksppstvl as value,b.KSPPDESC as description
from X$KSPPCV a, X$KSPPI b
where a.indx=b.indx and b.ksppinm = '_max_sleep_holding_latch'
NAME VALUE DESCRIPTION
------------------------------ ---------- ----------------------------------------
_max_sleep_holding_latch 4 max time to sleep while holding a latch
latch的类型和开机后的统计结果可以从v$latch看。
现在的问题是,latch设计之初的确是认为被锁了的资源会马上释放。而且栓等待的时间不会很长。
但是,总有事与愿违的时候。
万一有些latch(long wait latch)的确要等一个比较长的时间的时间,那么怎么办呢?
那就可以当成队列锁来管理,这里叫latch wait posting,使用了semaphore进行管理。
如果一种latch适用latch wait posting,那么当要使用这种latch的进程由于争抢latch失败时,这个进程首先会把自己放入一个等待队列。
而当持有相应资源的进程释放latch的时候,等待进程会得到原先持有那个latch的进程的通知,从而立即进入runnable状态。
这个过程是一个再次争抢的过程,也就是说被挂起进程再次争抢相应latch。
(为什么设计之初没有直接用队列锁呢?是由于从统计的角度看,这种latch大部分时候可以通过争抢来获得,而在比较少的情况下稍长。)
那么,哪些latch在sleep的时候可以被当成队列锁(也就是用semaphore)来管理呢?
oracle 8i中有一个参数,_LATCH_WAIT_POSTING,它可以来调整适用latch wait posting的范围。
_LATCH_WAIT_POSTING有三个取值:
_LATCH_WAIT_POSTING=0,所有latch都适用latch wait posting。
_LATCH_WAIT_POSTING=1,enqueue hash chains latch,shared pool latch,library cache latch这三种latch适用。
_LATCH_WAIT_POSTING=2,所有latch都适用latch wait posting。
从9i开始,_LATCH_WAIT_POSTING这个参数没有了。但是latch wait posting这种机制却没有消失。
只不过是不让用户自行调整罢了。
你可以这样查看有哪些long wait latch:
select * from v$latch where waiters_woken>0;
系统只有在运行一段时间后才能看见所有的long wait latch,因为v$latch视图反映的是latch的统计结果。
latch可以分成三种:
child latch, parent latch, solitary latch
当latch保护的是一个结构中的子结构的时候,这种latch叫child latch。
从v$latch_parent视图中可以看见child latch的统计结果。
而同一种child latch会有一个parent latch。
没有child latch的parent latch称作solitary latch。
v$latch_children视图当中包含了parent latch和solitary latch的统计结果。
前面我们提到过的_spin_count参数可以调整一个进程每一次的争抢次数。但是这种调整的影响是全局的。
9i中采取了更为精细的做法,它相当于给用户提供8个可以单独调整的spin count。
SMART>select indx, spin, yield, waittime from x$ksllclass;
INDX SPIN YIELD WAITTIME
---------- ---------- ---------- ----------
0 16000 0 1
1 16000 0 1
2 16000 0 1
3 16000 0 1
4 16000 0 1
5 16000 0 1
6 16000 0 1
7 16000 0 1
已选择8行。
其中的每一行都与init.ora参数文件当中的_LATCH_CLASS_n相对应。
如果你觉得哪些latch需要稍短或稍长的spin count,那你就可以使用这些设备。
举个例子,我们现在的cache buffers chains latches的sleep时间过长,给cpu造成比较严重的负担。
我们决定将cache buffers chains latches的spin count单独调整,使之有别于全局的spin count。
SMART>select latch#, name from v$latchname where name = 'cache buffers chains';
LATCH# NAME
---------- ------------------------------
97 cache buffers chains
修改参数文件之前,先来看一下我使用的参数文件和类型。
SMART>show parameter spfile
NAME TYPE VALUE
------------------------------------ ---------------------- ------------------------------
spfile string %ORACLE_HOME%\DATABASE\SPFILE%
ORACLE_SID%.ORA
此处得知,我使用的是spfile而不是pfile,那么我就要先从spfile生成一个pfile。
SMART>create pfile='init_new.ora' from spfile;
文件已创建。
接下来我们在参数文件当中加入:
*._latch_class_5 = "1000" #将latch class 5的spin count设置成1000
*._latch_classes = "97:5" #将97号latch的spin count绑定到latch class 5
shutdown后,再次启动oracle instance。
SMART> startup nomount pfile=d:\oracle\ora92\database\init_new.ora
ORACLE 例程已经启动。
Total System Global Area 135338868 bytes
Fixed Size 453492 bytes
Variable Size 109051904 bytes
Database Buffers 25165824 bytes
Redo Buffers 667648 bytes
SMART> alter database mount;
数据库已更改。
SMART> alter database open;
数据库已更改。
SMART> select indx, spin, yield, waittime from x$ksllclass;
INDX SPIN YIELD WAITTIME
---------- ---------- ---------- ----------
0 16000 0 1
1 16000 0 1
2 16000 0 1
3 16000 0 1
4 16000 0 1
5 1000 0 1
6 16000 0 1
7 16000 0 1
已选择8行。
SMART> select a.kslldnam, b.kslltnum, b.class_ksllt
2 from x$kslld a, x$ksllt b
3 where a.kslldadr = b.addr
4 and b.class_ksllt > 0;
KSLLDNAM KSLLTNUM CLASS_KSLLT
------------------------------ ---------- -----------
process allocation 3 2
cache buffers chains 97 5
latch会不会引起死锁?
会!
所以oracle将进程获取latch的方式分为willing-to-wait和no-wait。
当进程要获取的latch超过一个的时候,这些latch是按顺序获取的。
那么这个顺序又是什么呢?
表示这个顺序的是一个介于0到15的数,用2个字节的位图来表示。
0: 0000 0000 0000 0000
1: 0000 0000 0000 0001
2: 0000 0000 0000 0010
3: 0000 0000 0000 0100
...
14: 0010 0000 0000 0000
15: 0100 0000 0000 0000
系统中,每一个latch都有一个这样的数,来表示latch的level。
如果一个进程以willing to wait模式试图获取一个latch(假设这个latch为A,level为 n),那么系统会首先确保这个进程没有持有level大于等于n的latch。
这个latch level可以从X$KSLLD内部视图的KSLLDLVL看到。
X$KSLLD : [K]ernel [S]ervice [L]atch [L]ock [D]escriptor
KSLLDLVL : [K]ernel [S]ervice [L]atch [L]ock [D]escriptor [L]atch Le[V]e[L]
SMART>desc x$kslld;
名称 是否为空? 类型
----------------------- -------- ---------------
ADDR RAW(4)
INDX NUMBER
INST_ID NUMBER
KSLLDNAM VARCHAR2(64)
KSLLDADR RAW(4)
KSLLDLVL NUMBER
欲获取high level latch的进程在sleep阶段可能仍然会持有low level latch,从而使得需要low level latch的进程更加激烈的竞争。
low level latch可能会被长时间持有。
可以从v$latch视图的waits_holding_latch列得到相关的信息。
当这一字段所反映的情况十分糟糕的时候,那么需要dba进行干预。
如果当一个进程需要获取小于等于level n的latch时,采用willing to wait模式可能会引起死锁。
如果进程成功获取latch,没有死锁问题。
如果进程获得latch失败,那么它会释放掉自己的high level latches,然后立即以正确的顺序重新获取一遍latch。
这就是no wait模式了。
现在开始说一下enqueue lock。
Enqueue Lock是由Oracle Kernel Enqueue Service layer (KSQ)来负责管理的。
行锁(row level lock)
这里我们主要使用oracle的trace文件来进行分析。
开启两个session,我们这里称sesion A和session B。
session A:
SMART>create table t(a char(10), b int);
表已创建。
SMART>insert into t values('aaa',111);
已创建 1 行。
SMART>insert into t values('bbb',222);
已创建 1 行。
SMART>commit;
提交完成。
SMART>select file_id,block_id from dba_extents where owner=user and segment_name='T';
FILE_ID BLOCK_ID
---------- ----------
1 50649
SMART>alter system dump datafile 1 block 50650; /*要比BLOCK_ID大一个block号*/
系统已更改。
SMART>select p.spid from v$process p, v$session s,
2 (select sid from v$mystat where rownum<2) m
3 where s.paddr=p.addr and s.sid=m.sid;
SPID
------------------------
2628
打开udump\demo_ora_2628.ora文件。
/*
我们这里只看transaction layer(KTB)和data layer(KD)的部分。
*/
Block header dump: 0x0040c5da
Object id on Block? Y
seg/obj: 0x75d9 csc: 0x00.16809e3 itc: 2 flg: O typ: 1 - DATA
fsl: 0 fnx: 0x0 ver: 0x01
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0003.000.00000114 0x00800036.0036.35 --U- 2 fsc 0x0000.01680a2d
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
上面两行是数据块的事物槽,每一行叫做一个ITL(Interested Transaction List) slot。
Itl:事物槽编号。
Xid:事物编号,transaction id。
Uba:Undo block address。
Flag:事物状态标志。
---- 事物处于活动状态中,或者提交后直接clean out了。
C--- 已提交,锁被clean out了。
-B-- (我不知道这个标志是做什么用的)
--U- 已提交(也许很久之前提交的),需要clean out。
---T 事物在last full cleanout时仍然active。
Lck:这个事物锁了多少行数据。
Scn/Fsc: SCN or Free space credit。如果事物提交了,那么SCN表示commit SCN或者是SCN的上界(这和SCN的计算有关系),
如果没有提交,那么这里的前2个字节表示的就是事物在此block中free(动词)的字节数。
data_block_dump,data header at 0x306105c
===============
tsiz: 0x1fa0
hsiz: 0x16
pbl: 0x0306105c
bdba: 0x0040c5da
76543210
flag=--------
ntab=1
nrow=2
frre=-1
fsbo=0x16
fseo=0x1f7c
avsp=0x1f66
tosp=0x1f66
0xe:pti[0] nrow=2 offs=0
0x12:pri[0] offs=0x1f8e
0x14:pri[1] offs=0x1f7c
block_row_dump: <----数据
tab 0, row 0, @0x1f8e
tl: 18 fb: --H-FL-- lb: 0x1 cc: 2 <----看见这里的lb没有?0x1就是第一个ITL。
col 0: [10] 61 61 61 20 20 20 20 20 20 20 <----col 0占10个字节(跟我们定义的一样),数据如何存的以后讲。
col 1: [ 3] c2 02 0c <----col 1所占的字节数暂时为3,因为int类型实际的存储是可变的
tab 0, row 1, @0x1f7c
tl: 18 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [10] 62 62 62 20 20 20 20 20 20 20
col 1: [ 3] c2 03 17
end_of_block_dump
End dump data blocks tsn: 0 file#: 1 minblk 50650 maxblk 50650
我们现在打开session B
SMART>update t set b=10 where a='bbb';
已更新 1 行。
SMART>alter system dump datafile 1 block 50650;
系统已更改。
暂时没有提交,再看dump文件的结果。
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0003.000.00000114 0x00800036.0036.35 C--- 0 scn 0x0000.01680a2d
0x02 0x0007.026.0000011c 0x008002a8.0032.25 ---- 1 fsc 0x0001.00000000
block_row_dump:
tab 0, row 0, @0x1f8e
tl: 18 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [10] 61 61 61 20 20 20 20 20 20 20
col 1: [ 3] c2 02 0c
tab 0, row 1, @0x1f6b
tl: 17 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 62 62 62 20 20 20 20 20 20 20
col 1: [ 2] c1 0b
end_of_block_dump
End dump data blocks tsn: 0 file#: 1 minblk 50650 maxblk 50650
v$lock, v$transaction, v$transaction_enqueue 中大家自己去看吧。
session B提交.
SMART>commit;
提交完成。
SMART>alter system dump datafile 1 block 50650;
系统已更改。
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0003.000.00000114 0x00800036.0036.35 C--- 0 scn 0x0000.01680a2d
0x02 0x0007.026.0000011c 0x008002a8.0032.25 --U- 1 fsc 0x0001.01686955
block_row_dump:
tab 0, row 0, @0x1f8e
tl: 18 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [10] 61 61 61 20 20 20 20 20 20 20
col 1: [ 3] c2 02 0c
tab 0, row 1, @0x1f6b
tl: 17 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 62 62 62 20 20 20 20 20 20 20
col 1: [ 2] c1 0b
end_of_block_dump
行锁到此结束,下面讲讲buffer lock。
row level lock是用来控制磁盘上的并发读写的设备,而buffer lock是用来控制buffer cache中的block的并发读写。
以后讲等待事件的时候再仔细梳理一遍buffer lock。总而言之,buffer lock是一种应用在SGA的buffer cache中的lock。
字典锁(Data Dictionary Lock)
看名字就知道这种锁是用来保护什么的了。
当数据字典被引用的时候,数据字典是不能被删除的,其定义也不能被修改。
当系统对sql statement进行语法分析,语义分析,安全检查,生成备用查询计划,评估查询计划,定义输出格式,返回结果...
全部步骤完成之后,相应的字典锁才可以被释放。
一些锁可以被用来锁字典。比如row cache enqueue lock,library cache pins,DML lock。
锁模式
被锁的对象可以分成混合对象和简单对象。
复杂对象就好比一个table和table当中的rows,简单对象就好比buffer cache。
简单对象适合用下面三种锁:
Exclusive:排他锁,完全杜绝concurrent access。
Shared:共享锁,可以concurrent inspect/read,但是不可以修改。
Null:Steve Adams的书上说,这种锁啊,是当替换符用的。
如果一个会话cache了一个对象的信息,即便这个资源没有处于活动状态会话也会持有一个对应的null lock。
Null mode lock不会限制并发,但是当这个资源不再有效的时候,null lock会像trigger一样,通知会话清理相关cache。
除了上面三种锁之外,还有三种锁适用于混合对象。
Sub-shared:这种锁就是对混合对象的子对象分别使用共享锁,这样做可以提供更多的灵活性。
比如以部分区域可以共享,剩余的区域要被独占。
Sub-exclusive:与前者相反。
Shared-sub-exclusive:当会话需要一个混合对象的部分排他锁和整体共享锁时,就使用这种锁模式。
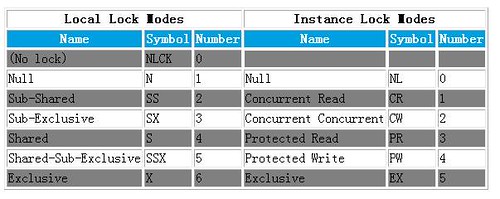
这六种锁模式适用于local lock和instance lock(也就是集群环境中,用以节点之间协作的enqueue)。
下面这张表给出了各种锁类型在dump文件中的缩写和等待事件中的数字编号。
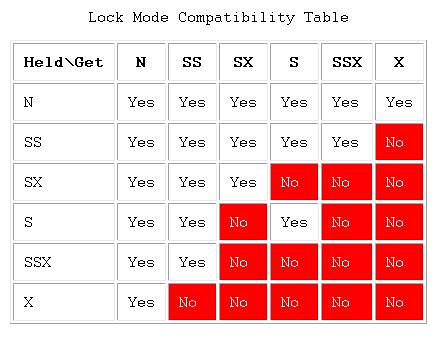
那些锁是相互兼容的也十分重要,这里给出这种关系的矩阵。
Oracle运行时就是依据上面这个表来判定会话应该得到锁还是被enqueue。
Oracle Kernel Enqueue Service layer (KSQ)负责管理所有enqueue。
会话在请求资源的时候,首先会去请求这个资源结构的锁。
在得到锁之前,系统会给这个资源当中用来描述锁的链表(引用的容器)加入一个锁的引用。
Enqueue resource可以从X$KSQRS (kernel service enqueue resource)或者V$RESOURCE试图当中看到。
SQL> select * from v$resource;
ADDR TY ID1 ID2
-------- -- ---------- ----------
6F644CE8 XR 4 0
6F644D40 TS 3 1
6F644EF8 CF 0 0
6F645058 RT 1 0
6F6450B0 RS 25 1
6F645538 MR 3 0
6F645590 MR 4 0
6F645698 MR 1 0
6F6456F0 MR 2 0
6F645748 MR 201 0
6F645A08 PW 1 0
6F646468 TA 6 1
(刚启动,还没有积攒起数据,嘿嘿)
Oracle 10g中V$EVENT_NAME试图里的PARAMETER2和PARAMETER3给出了ID1和ID2的含义。
在10g以前,这些含义没有给出,但是大家可以在网上找到。
TY: 指锁类型
ID1和ID2根据TY的不同,其含义也不同。
参数ENQUEUE_RESOURCES和_ENQUEUE_LOCKS定义了SGA中最多能有多少enqueue resource structure
每个enqueue resource structure都有三种锁引用的容器,分别是owner,waiter,convertor。
enqueue lock
select * from v$enqueue_lock;
给出了会话ID,锁类型,ID1和ID2,锁模式,请求模式,当前模式时间和blocking flag
查看TX锁和TM锁
select * from x$ktcxb where KTCXBLKP in (select kaddr from v$lock where type = 'TX');
select * from x$ktadm where KSQLKADR in (select kaddr from v$lock where type = 'TM');
Session A
SQL> test/test
已连接。
SQL> update blank set a='v' where a='cc';
已更新 1 行。
Session B
SQL> test/test
已连接。
SQL> update blank set a='dd';
Session C
SQL> select sid, event, p1, p1raw,
2 chr(bitand(P1,-16777216)/16777215)||chr(bitand(P1,16711680)/65535) type,
3 mod(P1, 16) "MODE" from v$session_wait where event like '%row lock%';
SID EVENT P1 P1RAW TYPE MODE
---------- ------------------------------ ---------- -------- ---- ----------
48 enq: TX - row lock contention 1415053318 54580006 TX 6
SQL>
select * from v$enqueue_stat
参考文献:
http://www.ixora.com.au/q+a/datablock.htm
《Oracle8i Internal Services For waits, latches, locks》
《Oracle Wait Interface: A Practical Guide to Performance Diagnostics & Tuning》
《Expert Oracle Database Architechture Oracle 9i and 10g Programming Techniques and Solutions》
http://www.revealnet.com/newsletter-v6/0905_E.htm
http://groups.google.com/group/Oracle-Internal/browse_thread/thread/5864abd39b3f8ffb
DBCA是好,但是作为DBA,必须要了解数据库创建的过程。
mkdir F:\oracle\product\10.2.0\flash_recovery_area
mkdir F:\oracle\product\10.2.0\oradata\replica
mkdir F:\oracle\product\10.2.0\admin\replica\bdump
mkdir F:\oracle\product\10.2.0\admin\replica\cdump
mkdir F:\oracle\product\10.2.0\admin\replica\udump
mkdir F:\oracle\product\10.2.0\admin\replica\scripts
#################init.ora###########################
nls_language="SIMPLIFIED CHINESE"
nls_territory="CHINA"
sga_target=167772160
job_queue_processes=10
dispatchers="(PROTOCOL=TCP) (SERVICE=replicaXDB)"
compatible=10.2.0.1.0
audit_file_dest=F:\oracle\product\10.2.0\admin\replica\adump
remote_login_passwordfile=EXCLUSIVE
pga_aggregate_target=16777216
db_domain=""
db_name=replica
control_files=("F:\oracle\product\10.2.0\oradata\replica\control01.ctl", "F:\oracle\product\10.2.0\oradata\replica\control02.ctl", "F:\oracle\product\10.2.0\oradata\replica\control03.ctl")
db_create_file_dest=F:\oracle\product\10.2.0\oradata
db_recovery_file_dest=F:\oracle\product\10.2.0\flash_recovery_area
db_recovery_file_dest_size=2147483648
open_cursors=300
undo_management=AUTO
undo_tablespace=UNDOTBS1
background_dump_dest=F:\oracle\product\10.2.0\admin\replica\bdump
core_dump_dest=F:\oracle\product\10.2.0\admin\replica\cdump
user_dump_dest=F:\oracle\product\10.2.0\admin\replica\udump
processes=150
db_block_size=8192
db_file_multiblock_read_count=16
####################################################
set ORACLE_SID=replica
oradim -new -sid replica -intpwd oracle -startmode M
sqlplus /nolog
conn / as sysdba
set echo on
spool F:\oracle\product\10.2.0\admin\replica\scripts\CreateDB.log
startup nomount pfile="F:\oracle\product\10.2.0\admin\replica\scripts\init.ora";
create spfile= FROM pfile='F:\oracle\product\10.2.0\admin\replica\scripts\init.ora';
CREATE DATABASE "REPLICA"
MAXINSTANCES 8
MAXLOGHISTORY 1
MAXLOGFILES 16
MAXDATAFILES 100
DATAFILE 'F:\oracle\product\10.2.0\oradata\replica\system.dbf'
SIZE 300M
AUTOEXTEND ON
NEXT 10240K
MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL
SYSAUX DATAFILE 'F:\oracle\product\10.2.0\oradata\replica\sysaux.dbf'
SIZE 120M
AUTOEXTEND ON
NEXT 10240K
MAXSIZE UNLIMITED
SMALLFILE DEFAULT TEMPORARY TABLESPACE TEMP
TEMPFILE 'F:\oracle\product\10.2.0\oradata\replica\temp.dbf'
SIZE 20M AUTOEXTEND ON NEXT 640K MAXSIZE UNLIMITED
SMALLFILE UNDO TABLESPACE "UNDOTBS1"
DATAFILE 'F:\oracle\product\10.2.0\oradata\replica\undo.dbf'
SIZE 200M AUTOEXTEND ON NEXT 5120K MAXSIZE UNLIMITED
CHARACTER SET AL32UTF8
NATIONAL CHARACTER SET AL16UTF16
LOGFILE GROUP 1 ('F:\oracle\product\10.2.0\oradata\replica\redo1.rdo') SIZE 51200K,
GROUP 2 ('F:\oracle\product\10.2.0\oradata\replica\redo2.rdo') SIZE 51200K,
GROUP 3 ('F:\oracle\product\10.2.0\oradata\replica\redo3.rdo') SIZE 51200K
USER SYS IDENTIFIED BY ORACLE USER SYSTEM IDENTIFIED BY ORACLE;
CREATE SMALLFILE TABLESPACE "USERS" LOGGING
DATAFILE 'F:\oracle\product\10.2.0\oradata\replica\user.dbf'
SIZE 5M
AUTOEXTEND ON
NEXT 1280K
MAXSIZE UNLIMITED
EXTENT MANAGEMENT LOCAL
SEGMENT SPACE MANAGEMENT AUTO;
ALTER DATABASE DEFAULT TABLESPACE "USERS";
@F:\oracle\product\10.2.0\db_1\rdbms\admin\catalog.sql; --*
@F:\oracle\product\10.2.0\db_1\rdbms\admin\catblock.sql;
@F:\oracle\product\10.2.0\db_1\rdbms\admin\catproc.sql; --*
@F:\oracle\product\10.2.0\db_1\rdbms\admin\catoctk.sql;
@F:\oracle\product\10.2.0\db_1\rdbms\admin\owminst.plb;
@F:\oracle\product\10.2.0\db_1\rdbms\admin\catclust.sql; --RAC
conn system/oracle
@F:\oracle\product\10.2.0\db_1\sqlplus\admin\pupbld.sql;
conn system/oracle
@F:\oracle\product\10.2.0\db_1\sqlplus\admin\help\hlpbld.sql helpus.sql;
conn / as sysdba
@F:\oracle\product\10.2.0\db_1\javavm\install\initjvm.sql;
@F:\oracle\product\10.2.0\db_1\xdk\admin\initxml.sql;
@F:\oracle\product\10.2.0\db_1\xdk\admin\xmlja.sql;
@F:\oracle\product\10.2.0\db_1\rdbms\admin\catjava.sql;
@F:\oracle\product\10.2.0\db_1\rdbms\admin\catexf.sql;
--其它部件参看文档
spool off
shutdown immediate
conn / as sysdba
execute utl_recomp.recomp_serial(); --重新编译所有的objects
编辑listener.ora文件
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_NAME=WHOLE)
(SID_NAME = PLSExtProc)
(ORACLE_HOME = F:\oracle\product\10.2.0\db_1)
(PROGRAM = extproc)
)
(SID_DESC =
(GLOBAL_DBNAME = replica)
(ORACLE_HOME = F:\oracle\product\10.2.0\db_1)
(SID_NAME = replica)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1))
(ADDRESS = (PROTOCOL = TCP)(HOST = 127.0.0.1)(PORT = 1521))
)
)
cmd> lsnrctl reload